Si tu página no está indexada, no existe para Google. Da igual que hayas invertido semanas en escribir el contenido, en diseñar la página o en optimizar el código. Si Google no la ha incluido en su índice, no va a aparecer en ningún resultado de búsqueda. Por eso, entender qué es la indexación y cómo funciona es uno de los pilares básicos del SEO.
En este artículo te explico desde cero qué es la indexación, qué factores la afectan y qué puedes hacer para controlarla en tu proyecto.
Lo que vamos a ver:
- Qué ocurre cuando Google indexa una página
- La diferencia entre indexabilidad e indexación
- Cómo decide Google qué URL es la canónica
- Qué factores técnicos bloquean o facilitan la indexación
- Cómo ver qué páginas tienes indexadas
- Cómo solicitar la indexación y cómo desindexar
- Los errores de indexación más frecuentes en Google Search Console
Qué es la indexación, según Google
Después de que Google rastrea una página, intenta comprender de qué trata. A ese proceso se le llama indexación.
Durante la indexación, Google analiza el contenido de texto, las etiquetas y los atributos clave de la página: el título, los atributos alt de las imágenes, los vídeos y otros elementos relevantes. A partir de ese análisis, determina si la página es una versión original o si es un duplicado de otra ya existente en Internet.
Solo la versión que Google considera canónica (es decir, la más representativa) puede aparecer en los resultados de búsqueda. Además, Google recopila indicadores sobre esa página: el idioma, el país donde se encuentra el contenido, la usabilidad, etc.
Hay algo importante que debes tener claro desde el principio: la indexación no está garantizada. No todas las páginas que Google rastrea acaban en su índice. Y la decisión depende, en gran parte, de la calidad del contenido, del estado técnico de la página y de las instrucciones que tú mismo le hayas dado a través de metadatos.
Indexabilidad vs. indexación
Son dos conceptos que se confunden con frecuencia y que no significan lo mismo.
La indexabilidad es la capacidad de una URL de ser indexada. Una URL es indexable cuando devuelve un código de respuesta 200, no tiene impedimentos técnicos y no hay ninguna instrucción que bloquee su entrada al índice.
La indexación es otra cosa: es el hecho de que Google ya ha analizado esa URL y la ha incluido en su índice en un momento determinado. Para que eso ocurra, Google también habrá evaluado su estado de canonicalización y habrá comprobado que el contenido tiene suficiente calidad.
Que una página sea indexable no significa que esté indexada. Y que esté indexada no significa que vaya a mantenerse así indefinidamente.
Cómo funciona la indexación por dentro
Cuando Google indexa una página, lo primero que hace es identificar el contenido principal. Si encuentra varias páginas con contenido igual o muy similar, elige la que considera más completa y útil para el usuario. Esa es la página canónica.
La URL canónica es la que Google rastreará con más frecuencia. Los duplicados se rastrearán con menos frecuencia para no desperdiciar recursos de rastreo en el sitio.
Para decidir qué URL es la canónica, Google tiene en cuenta varias señales: si la URL usa HTTP o HTTPS, si hay redirecciones, si la URL aparece en el sitemap y si existe un marcado rel canonical. A partir de ahí, utiliza esa página como fuente principal para evaluar el contenido y la calidad.
Lo más importante que puedes hacer aquí es ser coherente. Si quieres que Google entienda cuál es tu URL preferida, tienes que consolidar todas las señales en la misma dirección: el canonical, el sitemap, el enlazado interno y el código de respuesta deben apuntar a la misma URL. Mezclar señales contradictorias (por ejemplo, incluir una URL en el sitemap y señalar otra con el canonical) solo genera confusión y puede perjudicarte.
Los casos más habituales de duplicidad
Existen varios escenarios en los que Google puede encontrar contenido similar o idéntico en distintas URLs:
- Variantes de subdominio: el mismo contenido con www y sin www
- Variantes de protocolo: la versión HTTP y HTTPS del sitio.
- Variantes de dispositivo: una versión móvil y una de escritorio si no usas diseño responsive.
- Variantes dinámicas: URLs con parámetros de ordenación, filtrado o IDs de sesión.
- Variantes slash: que las URLs acaben en / o no (fuera de la home se considera duplicado).
- Variantes sindicadas: contenido replicado en distintos sitios.
- Variantes accidentales: el entorno de staging o desarrollo accesible públicamente.
En todos estos casos, necesitas tener clara cuál es tu versión preferida y consolidar las señales en torno a ella.
Qué factores afectan a la indexación
La indexación no depende de un único factor. Hay varios elementos técnicos que pueden facilitar o bloquear que tus páginas entren en el índice de Google.
Tecnología
La tecnología con la que está construida tu web puede ser un problema. Los sitios basados en JavaScript que no muestran el contenido ni los enlaces en el HTML renderizado pueden dificultar que Google entienda la página. Lo mismo ocurre con tecnologías que no permiten crear estructuras de URLs limpias, que no permiten mejoras de rendimiento o que devuelven un código de respuesta diferente a Googlebot del que ven los usuarios normales.
Códigos de respuesta
El código de respuesta que devuelve una URL es determinante para saber si puede indexarse:
- 200 OK: es el único código que permite que Google pase el contenido al proceso de indexación. Dentro de este código, que una URL sea indexable o no depende de otros factores: si tiene la directiva meta robots index o noindex, y si está correctamente canonicalizada.
- 3xx (redirecciones): una URL redirigida nunca se indexa. El 301 (redirección permanente) tiene mucho peso en la canonicalización; el 302 y el 307 (temporales) tienen menos peso.
- 4xx (errores de cliente): una URL con error no se indexa. Si ya estaba indexada, con el tiempo Google la eliminará del índice. El 410 indica que el contenido se ha eliminado de forma permanente y Google lo procesa más rápido que un 404 cuando quieres desindexar algo.
- 5xx (errores de servidor): de manera prolongada pueden conllevar la desindexación. Google trata los errores DNS de forma similar a los 5xx.
Directivas meta robots y X-Robots-Tag
Las directivas meta robots son instrucciones que le das a Google sobre qué debe hacer con una página. Se añaden en la sección <head> del HTML.
Las más relevantes para la indexación son:
noindex: le indica a Google que no quieres que esa página se indexe. Es la forma correcta de excluir URLs del índice, no el archivo robots.txt.
nofollow: impide que los enlaces de la página sean seguidos por el rastreador.
none: equivale a noindex + nofollow.
noimageindex: evita que las imágenes de esa página se indexen.
unavailable_after: permite indicar una fecha a partir de la cual la página no debe aparecer en los resultados.
Hay varios aspectos técnicos que debes tener en cuenta al trabajar con estas directivas. Los rastreadores solo pueden ver y respetar estas instrucciones si tienen acceso a la página. Si bloqueas una URL en robots.txt, Google no podrá leer el noindex y podría mantenerla indexada. Si varias reglas entran en conflicto, se aplica la más restrictiva. Evita inyectar o modificar las etiquetas meta robots con JavaScript; si no te queda más remedio, prueba exhaustivamente.
Para recursos que no son HTML (PDF, imágenes, XML) la instrucción correcta no es la etiqueta meta, sino el encabezado HTTP X-Robots-Tag.
Rel canonical
El rel canonical es una sugerencia (no una orden) que le das a Google para indicarle cuál es la URL original entre dos páginas iguales o muy similares.
Se puede añadir como etiqueta dentro del <head>, como cabecera HTTP o inyectado con JavaScript. Se debe usar con rutas absolutas, una instrucción por URL, y no se debe mezclar con noindex, porque son señales contradictorias: según John Mueller, de Google, en ese caso generalmente se aplica el canonical y se ignora el noindex.
Algunas buenas prácticas:
- No señales una URL en el sitemap y otra diferente con el canonical.
- No añadas rel canonical múltiples en una misma página, porque serán ignorados.
- Evita que la URL de destino del canonical sea un 404, un 301 o una página con noindex.
Profundidad de rastreo
La profundidad se refiere al número de clics que necesita un usuario (o un bot) para llegar a una página desde la home. La home es el nivel 0, las páginas enlazadas directamente desde ella son el nivel 1, y así sucesivamente.
Cuanto más profunda esté una página dentro de la jerarquía del sitio, menos importancia puede parecerle a Google. En SEO y UX se utiliza la regla de los 3 clics como referencia general: ninguna página debería estar a más de tres clics de la portada. No es una regla absoluta, pero es un buen punto de partida.
Para reducir la profundidad puedes añadir enlaces internos por tipología de página, optimizar el menú de navegación, mejorar la paginación y enlazar mapas de sitio HTML.
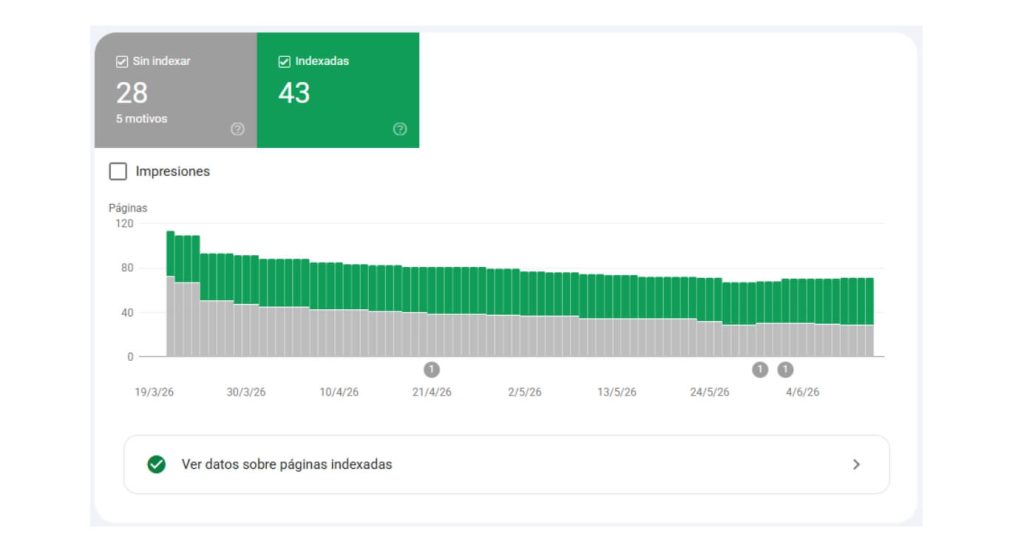
Cómo ver qué páginas tienes indexadas
La herramienta principal para esto es Google Search Console. En el apartado Indexación > Páginas puedes ver un listado completo de las URLs indexadas, filtrable por segmentos a partir de la estructura de las URLs.
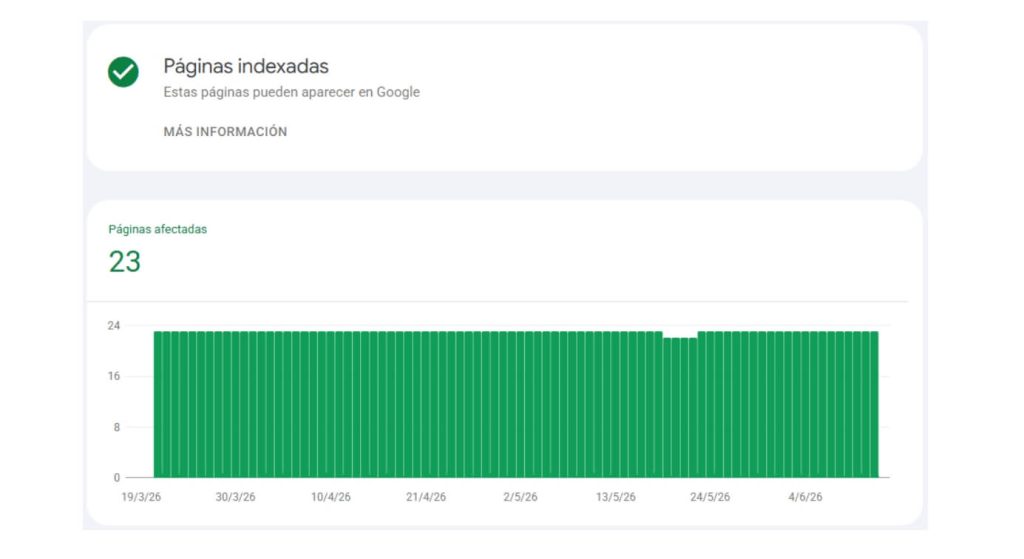
También puedes usar el comando site:tudominio.com en Google para obtener una estimación, aunque no es un dato exacto ni exhaustivo. Si lo combinas con otros comandos como filetype:pdf o inurl:blog, puedes encontrar contenidos indexados en formatos o secciones que quizás no esperabas.
Lo más útil a nivel profesional es crear un framework de segmentación: un documento donde cruces las URLs indexables de cada tipología de página (home, categorías, fichas de producto, artículos, etc.) con las URLs que realmente están indexadas. Esa diferencia porcentual te dice dónde tienes problemas y en qué segmento tienes que actuar primero.
Cómo pedir que Google indexe una URL
Para URLs individuales, la forma más directa es usar la herramienta de Inspección de URLs en Google Search Console. Introduces la URL, pulsas en «Probar URL publicada» y luego en «Solicitar indexación».
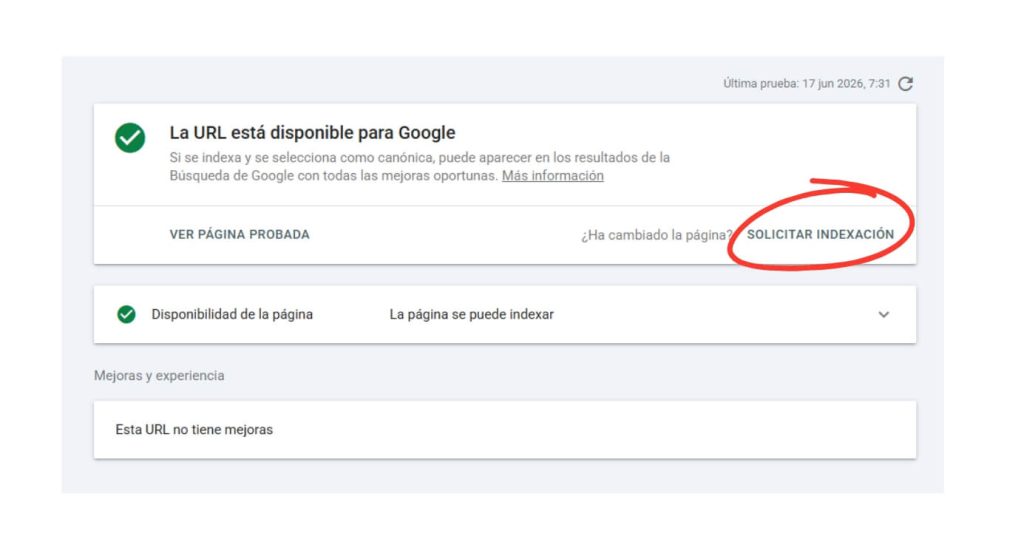
Para conjuntos de URLs, la vía más eficaz es el sitemap. Enviar un sitemap a Google Search Console le ayuda a descubrir URLs que de otra forma podría no encontrar fácilmente. Eso sí, el sitemap no garantiza la indexación ni afecta al ranking de las páginas. Es una ayuda al proceso de rastreo y descubrimiento, no una orden.
Otras formas de facilitar que una página se indexe: añadir enlaces internos desde páginas importantes y muy rastreadas, conseguir enlaces externos, compartir la URL en redes sociales y generar tráfico hacia ella.
Cómo desindexar páginas
Cuando quieres que Google elimine una página de su índice tienes dos vías principales.
La primera es añadir el método de desindexación correspondiente (un 404, un 410, una etiqueta noindex o hacer el contenido privado con contraseña) y esperar a que Google vuelva a rastrear la URL y la desindexe por sí solo.
La segunda es usar la herramienta de Retirada de URLs en Google Search Console, que acelera el proceso. Pero hay un detalle importante: si pasados seis meses esa URL no tiene ningún método de desindexación activo, Google volverá a indexarla. La retirada es temporal; el método de desindexación tiene que estar en la página.
Lo que no debes hacer es bloquear la URL en robots.txt esperando que eso la desindexe. Si Google no puede acceder a la página, no puede leer el noindex. Y si la URL recibe enlaces desde sitios con autoridad, Google puede mantenerla indexada aunque no conozca su contenido.
Errores frecuentes de indexación en Google Search Console
En el informe de Indexación > Páginas, Google te muestra las URLs que no están indexadas agrupadas por motivo. Los más frecuentes son estos:
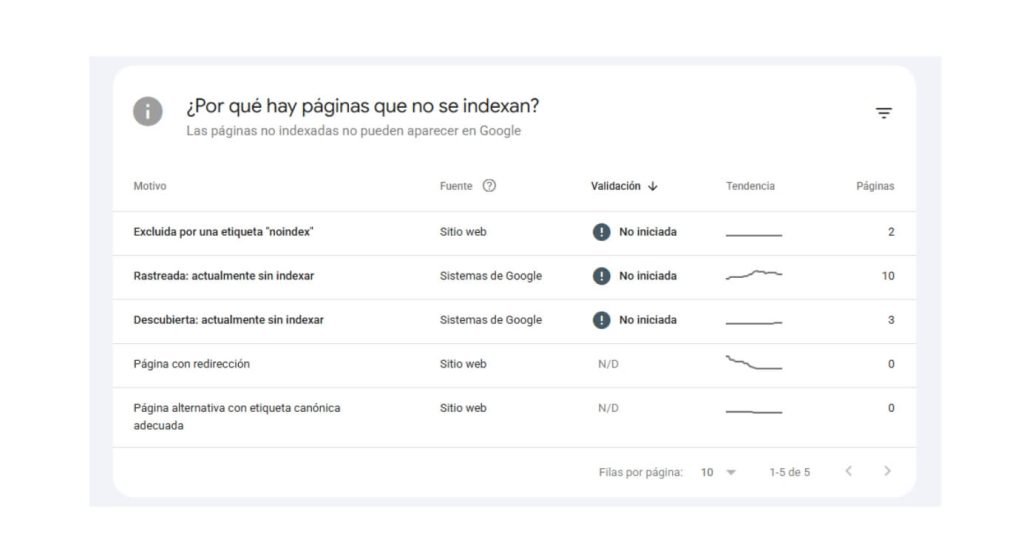
«Descubierta: actualmente sin indexar»: Google conoce la URL pero todavía no la ha rastreado ni indexado. Puede indicar problemas de presupuesto de rastreo, falta de enlaces internos o contenido de baja prioridad para Google. Revisa la calidad de las páginas afectadas, añade enlaces internos desde páginas importantes y asegúrate de que tu robots.txt no está bloqueando páginas de forma involuntaria.
«Rastreada: actualmente sin indexar»: Google ha rastreado la página pero ha decidido no indexarla. Suele ser un problema de calidad o de contenido duplicado. Si las páginas afectadas tienen contenido único y valioso, añádelo, envía las URLs desde GSC y trabaja el enlazado interno hacia ellas.
«Duplicada: Google ha elegido una versión canónica diferente a la del usuario»: Google considera que la URL correcta es otra distinta a la que tú has señalado. Revisa que no existan señales en conflicto: el canonical debe apuntar a la URL correcta, esa URL debe recibir enlaces internos y debe estar en el sitemap.
Puntos clave para gestionar la indexación
Define qué URLs quieres indexar. Sin eso, no puedes detectar cuándo algo no funciona. Establece las URLs canónicas o preferidas de tu proyecto y consolida todas las señales alrededor de ellas. No busques soluciones complejas: las señales SEO son técnicamente sencillas de implementar. Lo que marca la diferencia es el contenido y la coherencia técnica. Y recuerda que la arquitectura web y el rendimiento también impactan en el rastreo y la indexación, no solo en la experiencia de usuario.
Si necesitas ayuda para analizar la indexación de tu web o para definir una estrategia técnica SEO, puedo ayudarte. Puedes contactar conmigo (: